

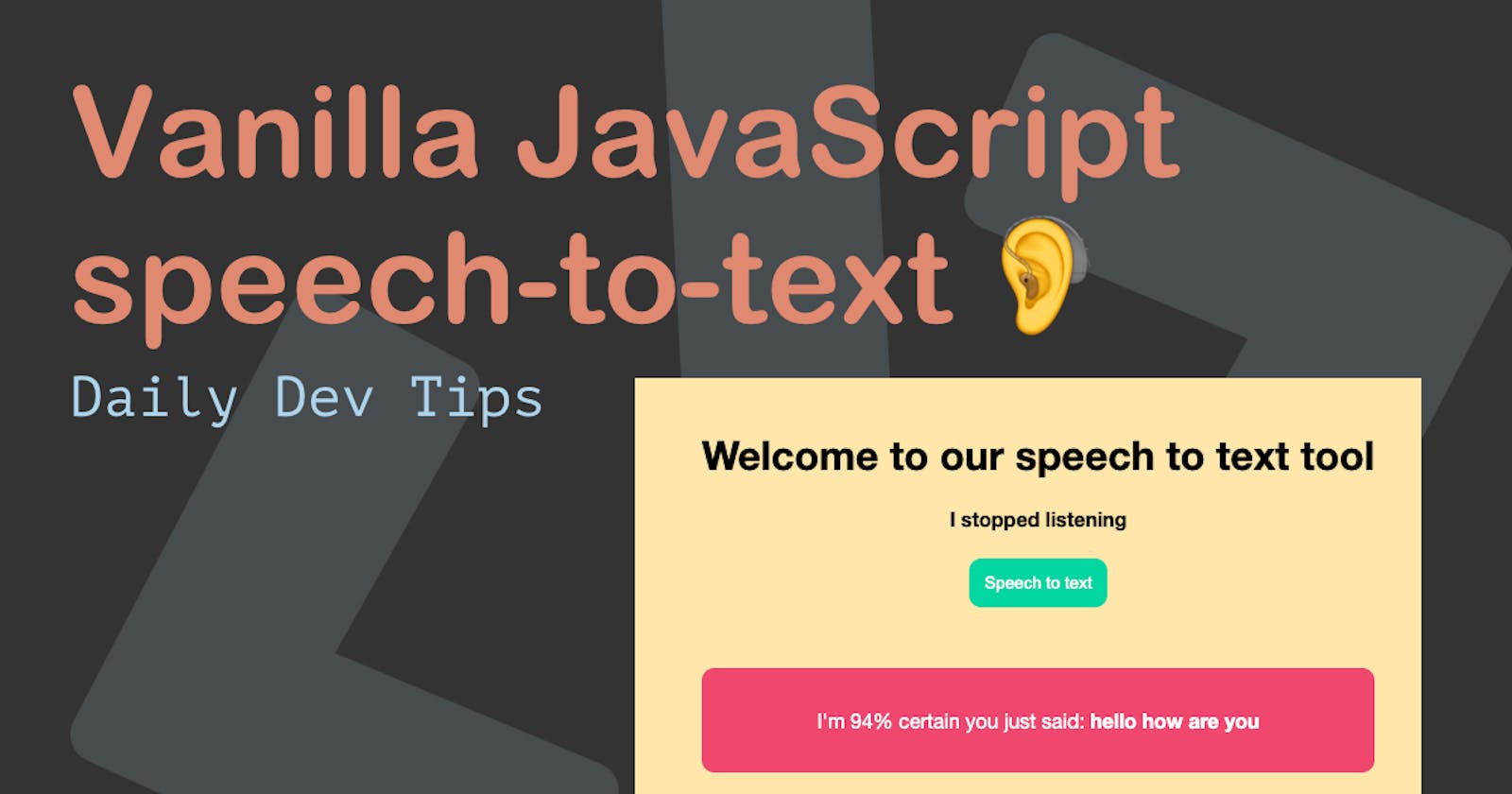


After we build a JavaScript text-to-speech application, now let's turn the tables and make the computer listen to what we say!
We will create a piece of code that will start listening to us and compile to text.
For this example, we will use the SpeechRecognition interface.
This interface comes with quite a few properties, which we won't all be using for this demo.
grammars: Returns a set ofSpeechGrammarobjectslang: Defaults to the HTML lang attribute, but can be manually setcontinuous: Can be set to true, default is false and means it will stop after it thinks you're doneinterimResults: Boolean that tells us if the interim results should be returned as well.maxAlternatives: The recognition will guess what you say and by default return only 1 result. We can however, tell it to return more.serviceURI: By default we use the user agent speech service, but we can define a specific one!
The end result of what we are building will look like this:
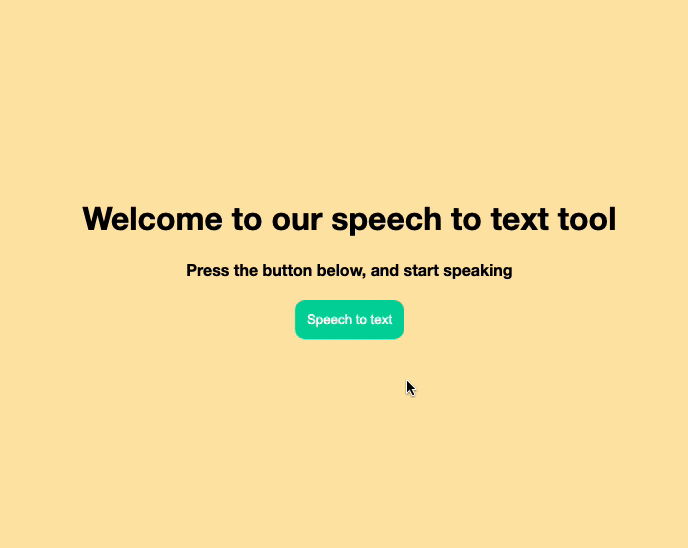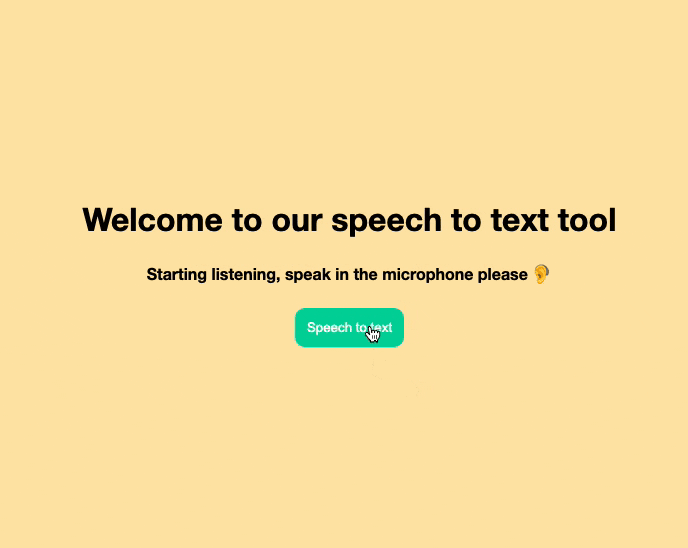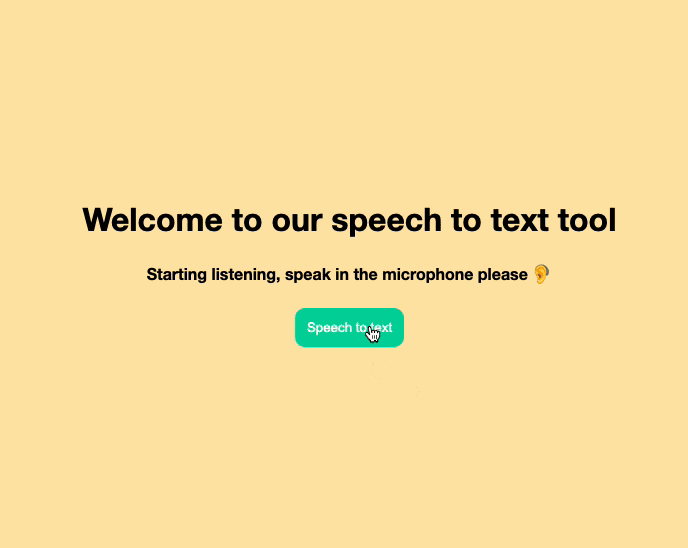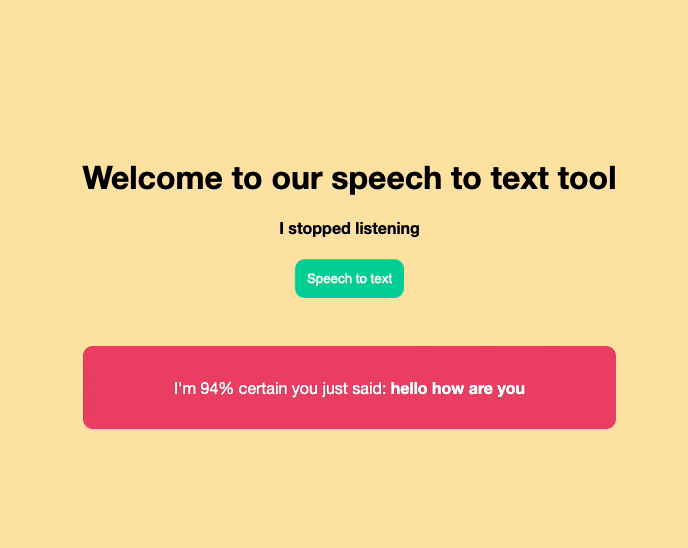
Detecting browser support
Since not all browsers fully support this method, we will need to detect if our browser has this option.
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
Here we define a const to check if the support is defined.
We can then easily check of this const.
if (SpeechRecognition !== undefined) {
// Do the speech stuff
} else {
console.warn('sorry not supported 😭');
}
JavaScript speech to text
Now that we defined our browser supports this feature, we can go ahead a start working on recording our voice.
Let's first make a very simple HTML setup.
We are going to need a status text to tell the user what's going on, we also need a button to start listening. And an output div to place our results in.
<div>
<h1>Welcome to our speech to text tool</h1>
<h4 id="status">Press the button below, and start speaking</h4>
<button onclick="startRecognition()">Speech to text</button>
<div id="result" class="hide"></div>
</div>
Now let's start by defining these as variables so we can use them.
const status = document.getElementById('status'),
result = document.getElementById('result');
The next step is to create our startRecognition function.
startRecognition = () => {
if (SpeechRecognition !== undefined) {
let recognition = new SpeechRecognition();
} else {
console.warn('sorry not supported 😭');
}
};
If the recognition is supported, we create a new SpeechRecognition interface.
Now this doesn't do anything yet because it isn't started.
But before we start it, let's define some events that it comes with to capture states.
First, we'll define the start.
recognition.onstart = () => {
status.innerHTML = `Starting listening, speak in the microphone please 🦻`;
output.classList.add('hide');
};
This function will be called once the onstart event is triggered. We will use it to give the user a status update that we are listening.
The next job is to see when the user is done speaking.
recognition.onspeechend = () => {
status.innerHTML = `I stopped listening `;
recognition.stop();
};
Here we tell the user in our status element that we stopped listening to them. We also manually stop the recognition.
Now we need to receive the actual results.
recognition.onresult = result => {
console.log(result);
};
This function is called when the results are in, and they come as a SpeechRecognitionEvent.
Which looks like this:
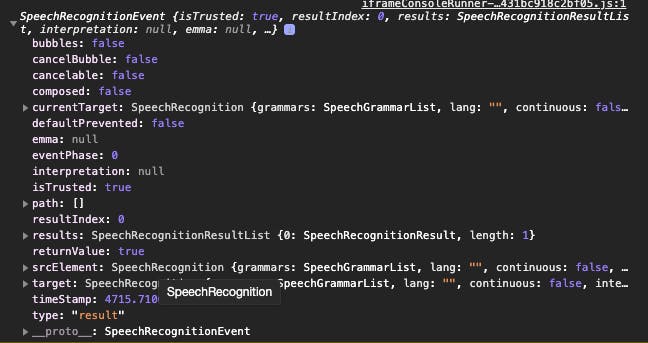
We are interested in the results however.
These are parsed as SpeechRecognitionResults and as mentioned, can be multiple if you use the maxAlternatives.
In our example, we will stick to one, and such a result will look like this:
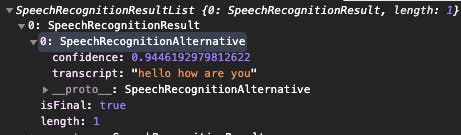
You can see where this is going right. We can use the transcript to get the text it guessed we spoke. And there is a confidence which is how certain it is you said something.
Let's add this to our output element.
recognition.onresult = result => {
output.classList.remove('hide');
output.innerHTML = `I'm ${Math.floor(
result.results[0][0].confidence * 100
)}% certain you just said: <b>${result.results[0][0].transcript}</b>`;
};
Now, all we have to do is add the start!
recognition.start();
The first time we run this and click the button, it will prompt our microphone access.
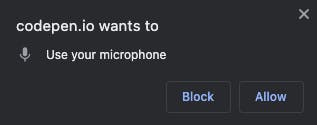
Once we have done that, we can start speaking and see the transcript coming in our output.
Wow, we just made the computer listen to us, how awesome right.
You can find this full demo on the following Codepen.
Note: For the demo open it in Codepen itself.
Browser Support
Sad enough, this isn't a fully supported feature yet! I think it will be bigger and bigger since speech, in general, is getting more needed for the web.

Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on Facebook or Twitter